Apache Spark Framework uses a master-slave architecture which consist of
a driver program which runs on master node and many executors which
runs across the worker nodes in the cluster.Apache Spark can be used for
batch processing and real-time processing as well.

What is spark Driver
The executor memory is basically a
measure on how much memory of the worker node application will utilize.
Every spark application has same fixed heap size and fixed number of
cores for a spark executor. The heap size is what referred to as the
Spark executor memory which is controlled with the spark.executor.memory
property of the –executor-memory flag. Every spark application will
have one executor on each worker node.
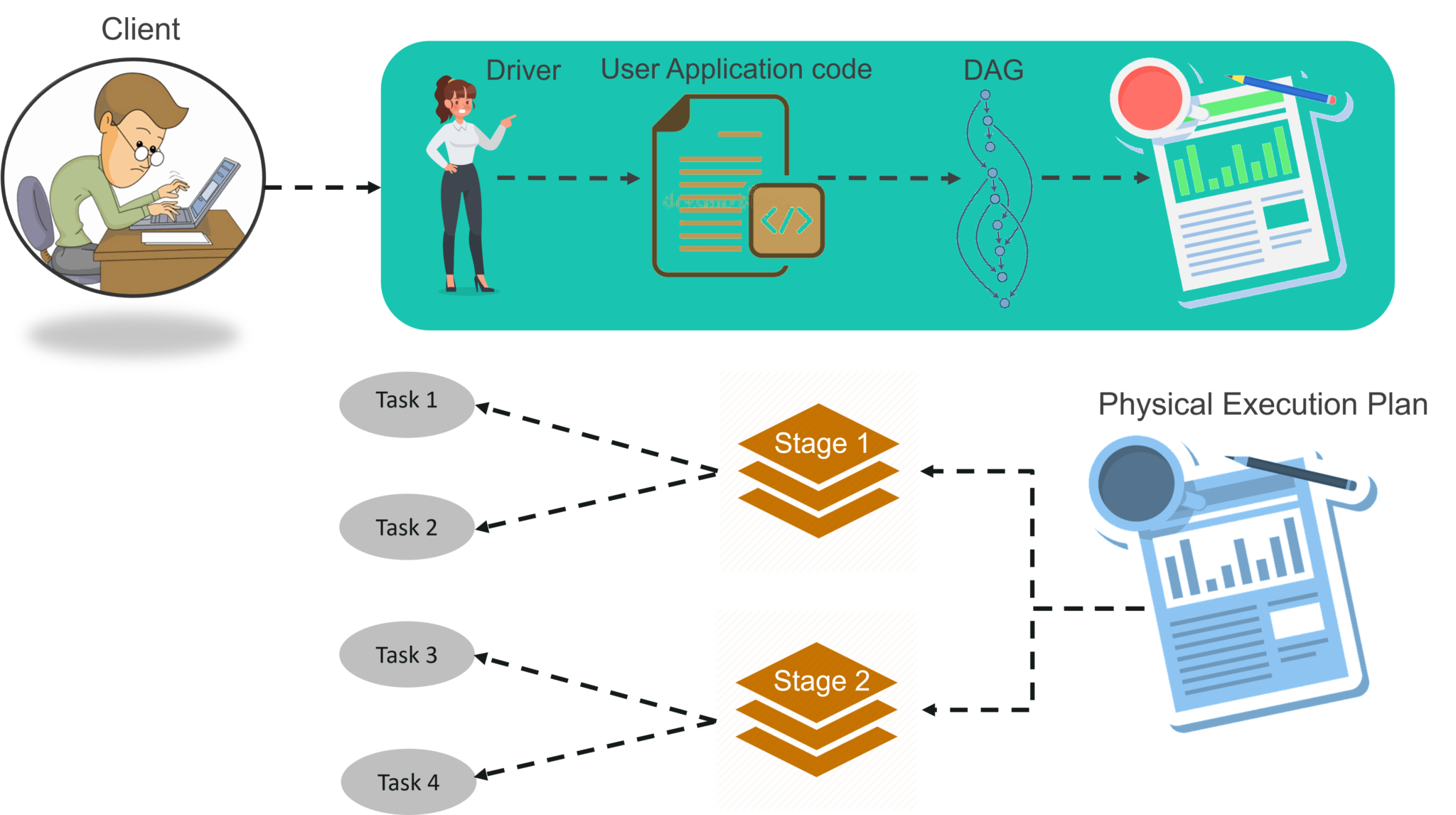
STEP 1: The client submits spark user application code. When an application code is submitted, the driver performs several tasks on the application and identify whether transformations and actions are present in the application. Implicitly converts user code that contains transformations and actions into a logically directed acyclic graph called DAG. At this stage, it also performs optimizations such as pipelining of transformations.
STEP 2: After that, it converts the logical graph called DAG into physical execution plan with many stages. After converting into a physical execution plan, it creates physical execution units called tasks under each stage. Then the tasks are bundled and sent to the cluster.As we discussed earlier driver identifies transformations. It also sets stage boundaries according to the nature of transformation. Narrow Transformations – Transformation process like map() and filter() comes under narrow transformation. In this process, it does not require to shuffle the data across partitions. Wide Transformations – Transformation process like ReduceByKey comes under wide transformation. In this process, it is required shuffling the data across partitions. After all, DAG scheduler makes a physical execution plan, which contains tasks. Later on, those tasks are joint to make bundles to send them over the cluster.
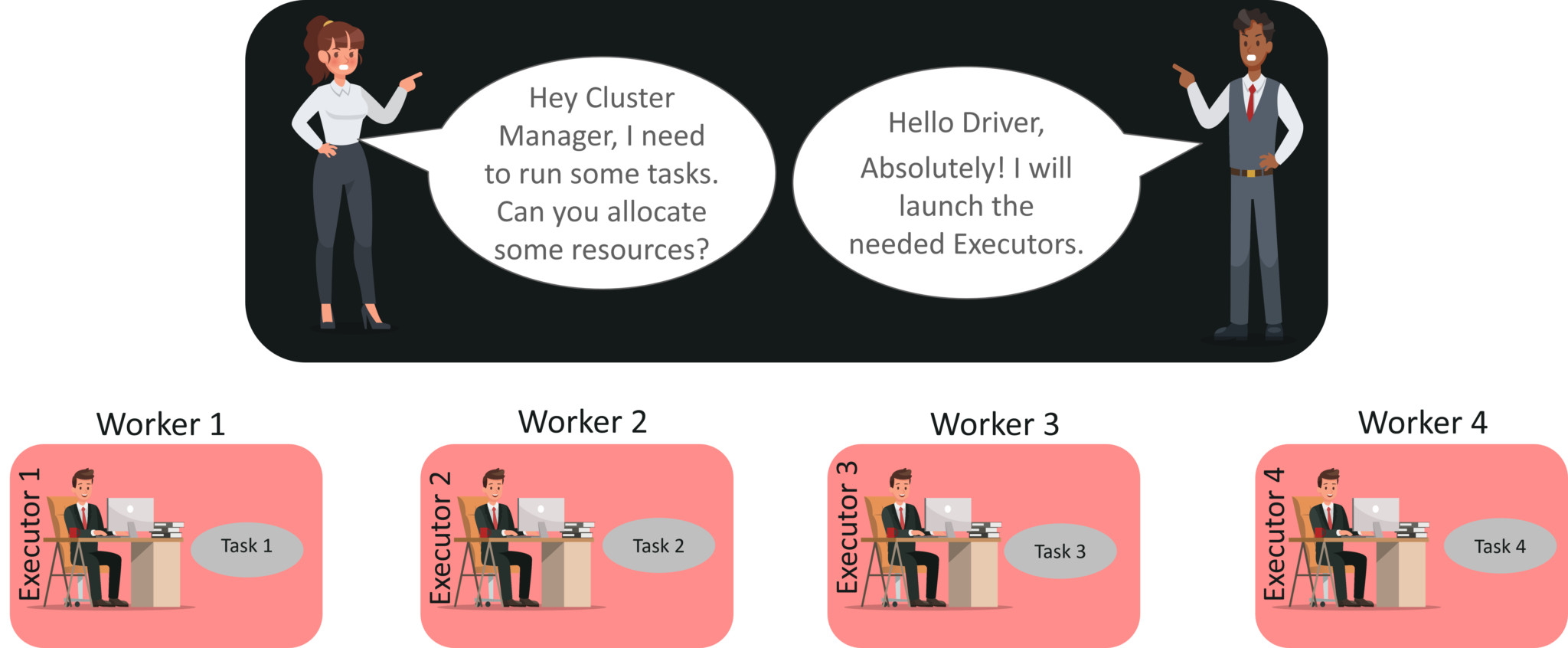
STEP 3: Now the driver talks to the cluster manager and negotiates the resources. Cluster manager launches executors in worker nodes on behalf of the driver. At this point, the driver will send the tasks to the executors based on data placement. When executors start, they register themselves with drivers. So, the driver will have a complete view of executors that are executing the task.
STEP 4: During the course of execution of tasks, driver program will monitor the set of executors that runs. Driver node also schedules future tasks based on data placement.
What is spark Driver
Spark Driver is the program that runs on the master node of the machine
and it calls the main program of applications and also creates the spark
context.Its declares transformations and actions on RDDs and submit
such application to master. In simple terms, a driver in Spark creates
SparkContext, connected to a given Spark Master. The Spark Driver also contains various other components like DAG Scheduler, Task Scheduler, Backend Scheduler, and Block Manager which are responsible for translating the user written code into jobs which are actually executed on the cluster.
- The driver program that runs on the master node of the spark cluster schedules the job execution and negotiates with the cluster manager.
- The driver process is responsible for converting a user application into smaller execution units called tasks. These tasks are then executed by executors which are worker processes that run the individual tasks.
- It translates the RDD’s into the execution graph and splits the graph into multiple stages.
- Driver stores the metadata about all the Resilient Distributed Databases and their partitions.
- Cockpits of Jobs and Tasks Execution -Driver program converts a user application into smaller execution units known as tasks. Tasks are then executed by the executors i.e. the worker processes which run individual tasks.
- Driver exposes the information about the running spark application through a Web UI at port 4040.
What is Spark Context?
- Main entry point for Spark functionality.
- A SparkContext represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
- Spark context sets up internal services and establishes a connection to a Spark execution environment.
- A Spark context is essentially a client of Spark’s execution environment and acts as the master of your Spark application.
Cluster Manager
The SparkContext can work with various Cluster Managers, like Standalone
Cluster Manager, Yet Another Resource Negotiator (YARN), or Mesos,
which allocate resources to containers in the worker nodes. The work is
done inside these containers.
- Mesos
- YARN
- Spark Standalone
Worker Node
- Worker
node is basically the slave node whose job is to basically execute the tasks.
- Master node assigns work and worker
node performs the assigned tasks.
- Spark Context takes the job, breaks the job in tasks and distribute them to the worker nodes. These tasks work on the partitioned RDD, perform operations, collect the results and return to the main Spark Context.
- If you increase the number of workers, then you can divide jobs into more partitions and execute them parallelly over multiple systems. It will be a lot faster.
- Worker
nodes process the data
stored on the node and report the resources to the master. Based on the
resource availability, the master schedule tasks. Whenever an RDD is
created in the Spark Context, it can be distributed across many worker
nodes and can also be cached there.
- Worker nodes execute the tasks which are assigned by the Cluster Manager and returns it back to the Spark Context.
Spark Executor
Executors
are Spark processes that run computations and store the data on the
worker node.Executor is a distributed agent responsible for the
execution of tasks. Every spark applications has its own executor
process. Executors usually run for the entire lifetime of a Spark
application and this phenomenon is known as “Static Allocation of
Executors”. However, users can also opt for dynamic allocations of
executors wherein they can add or remove spark executors dynamically to
match with the overall workload.
Executor Meomery- Executor performs all the data processing.
- Reads from and Writes data to external sources.
- Executor stores the computation results data in-memory, cache or on hard disk drives.
- Interacts with the storage systems.
Spark process Flow
Inside the driver program, the first thing you do is- create a SparkSession(Spark Context). Assume that the SparkSession(Spark context) is a gateway to all the Spark functionalities. It is similar to your database connection. Any command you execute in your database goes through the database connection. Likewise, anything you do on Spark goes through Spark context.
- Spark context works with the cluster manager to manage various jobs. The driver program & Spark context takes care of the job execution within the cluster.
- Spark Context takes the job and is split into multiple tasks which are distributed over the worker node. Anytime an RDD is created in Spark context, it can be distributed across various nodes and can be cached there.
- Worker nodes are the slave nodes whose job is to basically execute the tasks. These tasks are then executed on the partitioned RDDs in the worker node and hence returns back the result to the Spark Context.
- If you increase the number of workers, then you can divide jobs into more partitions and execute them parallely over multiple systems. It will be faster.With the increase in the number of workers, memory size will also increase & you can cache the jobs to execute it faster.
STEP 1: The client submits spark user application code. When an application code is submitted, the driver performs several tasks on the application and identify whether transformations and actions are present in the application. Implicitly converts user code that contains transformations and actions into a logically directed acyclic graph called DAG. At this stage, it also performs optimizations such as pipelining of transformations.
STEP 2: After that, it converts the logical graph called DAG into physical execution plan with many stages. After converting into a physical execution plan, it creates physical execution units called tasks under each stage. Then the tasks are bundled and sent to the cluster.As we discussed earlier driver identifies transformations. It also sets stage boundaries according to the nature of transformation. Narrow Transformations – Transformation process like map() and filter() comes under narrow transformation. In this process, it does not require to shuffle the data across partitions. Wide Transformations – Transformation process like ReduceByKey comes under wide transformation. In this process, it is required shuffling the data across partitions. After all, DAG scheduler makes a physical execution plan, which contains tasks. Later on, those tasks are joint to make bundles to send them over the cluster.
STEP 3: Now the driver talks to the cluster manager and negotiates the resources. Cluster manager launches executors in worker nodes on behalf of the driver. At this point, the driver will send the tasks to the executors based on data placement. When executors start, they register themselves with drivers. So, the driver will have a complete view of executors that are executing the task.
STEP 4: During the course of execution of tasks, driver program will monitor the set of executors that runs. Driver node also schedules future tasks based on data placement.
No comments:
Post a Comment